Foundry

Udith Vaidyanathan
CEO & Co-Founder

Over time at LogicFlo, we've had a front-row seat to how AI shows up inside pharma and medical communications workflows.
Here's what I keep hearing: everyone has a pilot. Almost nobody has a production system.
I speak at conferences, sit in on advisory boards, join steering committee calls - and the pattern is remarkably consistent. Someone shows a snazzy looking demo, and the entire room gets excited - many times, enough for a pilot to get funded. And the pilot always works well enough in a controlled setting. And then... it just kind of stays there. Perpetual pilot purgatory.
When I ask why, the answers converge on a single uncomfortable truth: people don't trust it enough to go live. And when I push on why they don't trust it, it's not because the AI isn't good. It's because they have no way to prove it's good. No structured evidence or ongoing measurement, or mechanism to catch it when it stops being good.
Think about it this way. Imagine someone handed you a new drug and said, "We tested it a few times, it seemed to work, the team felt good about it." You would laugh them out of the room. You'd ask about the trial design, the endpoints, the statistical plan, the monitoring protocol. You'd want to see data, not vibes.
And yet that's essentially how most pharma companies are evaluating their AI systems right now. A few people try it. It looks reasonable. Someone types "looks good" in a Teams chat. Ship it.
We can do better than this. And frankly, the frameworks already exist, we just haven't adapted them for our world yet.
Recently, Anthropic published a detailed engineering guide on building evaluation frameworks (called "evals") for AI agents. It's written for a general technical audience, but the underlying logic maps remarkably well to how pharma already thinks about quality. The core insight is one that should resonate with anyone who's ever managed a validated system: without structured evaluation, you're developing in the dark. You have no reliable feedback on how changes affect performance.
For regulated industries, that's not just an engineering problem. It's a risk management problem.
What This Article Covers
Before we dive in, here's a roadmap of what we'll walk through - think of it as the executive summary for the scroll-averse.
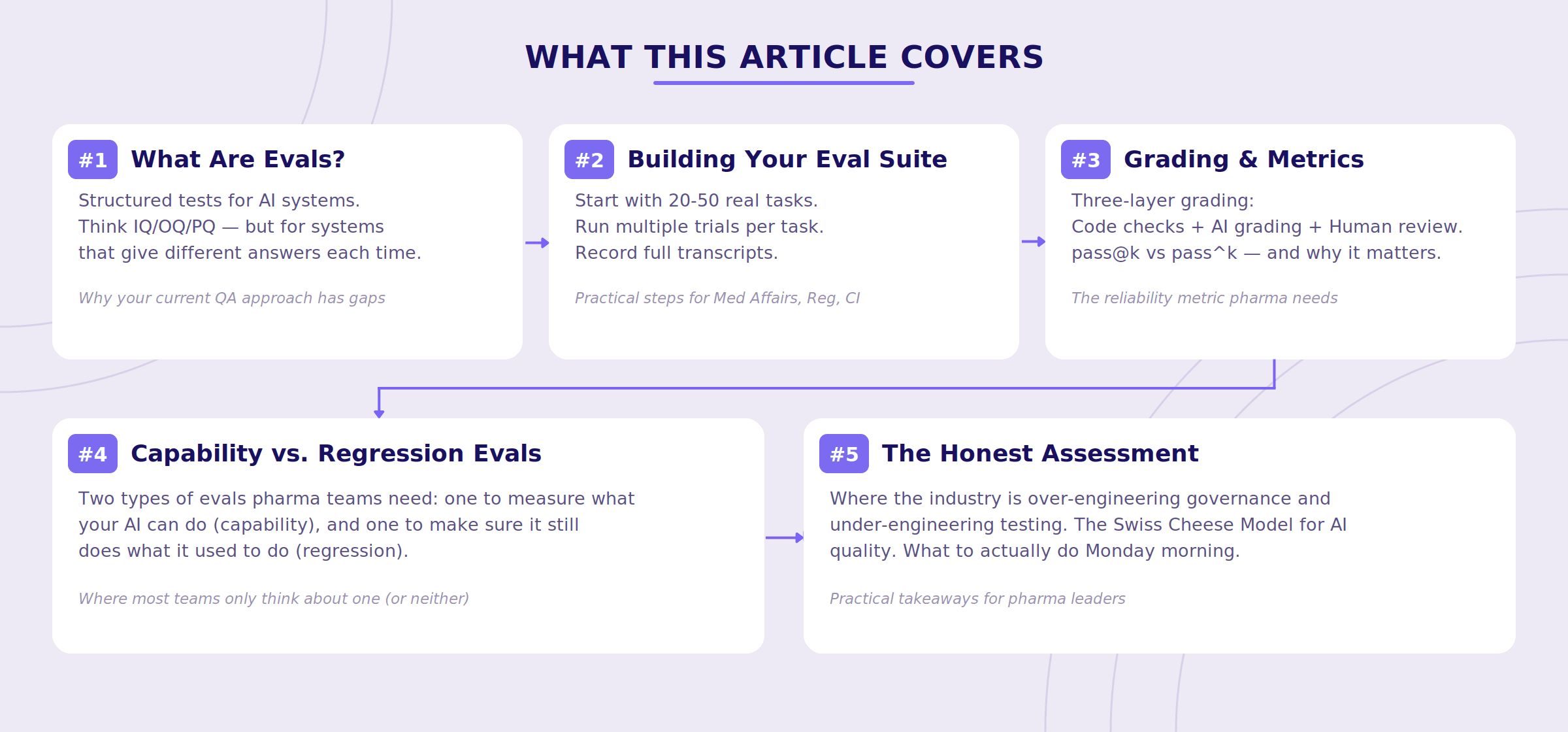
What Are AI Evals, Really?
Strip away the jargon, and an eval is just a structured test for an AI system. You give the system a task. You check whether it completed it correctly. You do this many times, across many tasks, and you track the results over time.
If you've spent any time in pharma, this should feel familiar. It's essentially IQ/OQ/PQ, but for systems that have a personality disorder. (I'm kidding. Mostly.)
Traditional validation tests deterministic systems. You click the button, the same thing happens every time. That's the whole point - reproducibility. AI systems are probabilistic. You give the same prompt on a Tuesday and a Thursday and you might get two meaningfully different answers. This isn't a bug, it's how large language models work. But it means your testing approach needs to account for variability in a way that your current GxP validation frameworks were never designed for.
It's like the difference between validating a calculator and validating a new hire. The calculator gives you the same answer every time. The new hire gives you different answers depending on how they slept, what they had for lunch, and whether Mercury is in retrograde. Both might be correct, but you'd test them very differently.
Consider an AI assistant supporting Medical Affairs teams. An evaluation task might ask the system to summarize the efficacy results of a Phase III clinical trial for a physician audience. The eval would then check:
Did it capture the primary and key secondary endpoints correctly?
Did it include relevant safety data?
Did it avoid unsupported claims or exaggerated language?
Does it sound like something a med comms team would actually use, or does it read like someone fed a Wikipedia article through a blender?
Run that test once and you know whether the system can do the task. Run it fifty times and you know whether you can count on it.
Why AI Systems Are Harder to Evaluate Than Traditional Software
Here's where it gets interesting, and where a lot of pharma teams get caught off guard.
Modern AI tools increasingly behave like agents, meaning they don't just answer a question. They perform multiple steps before producing a final result. Think of it less like a calculator and more like a junior analyst you've asked to research something.
For example, an AI research assistant might:
Search literature databases
Retrieve relevant publications
Extract trial endpoints
Compare findings across studies
Generate a summary or table
Because the system performs several steps, failures can occur at any point in the chain. If the final output is wrong, it's often not obvious where things went sideways. Was the wrong publication retrieved? Did the system misread a hazard ratio? Did it summarize the right data but draw the wrong conclusion?
It's like getting a bad medical response letter and trying to figure out whether the problem was the source literature, the person who reviewed it, or the person who drafted it. Except now all three of those "people" are the same AI, and none of them left notes.
Anthropic calls this flying blind. And in our experience working with pharma teams, it's where most AI implementations currently sit. The system produces an output, and the only real test is someone eyeballing it, and if it looks reasonable, it ships. There's no structured way to trace what happened between the prompt and the response, and no systematic way to catch when something changes.
That's fine for a pilot. It's terrifying for production.
A Practical Framework for Pharma AI Evals
Here's what we've found works, drawing on Anthropic's framework and our own experience building for pharma content workflows.
Step 1: Start with real tasks, not hypothetical ones
The strongest eval suites are built from tasks your teams actually perform. Not abstract benchmarks. Not demo scenarios cooked up for a steering committee. Real work.
Anthropic recommends starting with 20–50 tasks, enough to establish a meaningful baseline without turning this into a multi-quarter validation project. That's a few days of work for a cross-functional team, not a six-month odyssey.
For pharma, those tasks might include:
Medical Affairs
Summarize a clinical publication for a specific audience (physician, payer, patient)
Draft a response to an unsolicited medical inquiry about dosing or off-label use
Generate an advisory board briefing document from recent trial readouts
Regulatory
Review a promotional claim and determine whether it's consistent with approved label language
Identify missing safety statements or fair balance issues in a draft document
Flag language that might constitute an unsupported superiority claim
Competitive Intelligence
Extract primary and secondary endpoints from a competitor's Phase III readout
Compare efficacy results across trials (with appropriate caveats about cross-trial comparison)
Publications & Med Comms
Draft a plain-language summary of a clinical study
Generate a slide narrative from a set of data tables
The point is specificity. "Summarize this paper" is not a useful eval task. "Summarize the efficacy and safety results of this Phase III NSCLC trial for a community oncologist audience, including the primary endpoint, key secondary endpoints, and any Grade 3+ adverse events" - that's a useful eval task. The difference is the same as the difference between "test this drug" and an actual clinical protocol.
Step 2: Run multiple trials, not just one
Because AI outputs vary between runs, running a task once tells you almost nothing about reliability. Evaluation systems run multiple trials of each task — three, five, sometimes more — to measure not just whether the system can get the right answer, but how often it does.
A system summarizing a clinical study might produce three different versions across three runs. One might foreground the efficacy data. Another might lead with the safety profile. A third might reorganize the content entirely. All three might be acceptable — or one might quietly drop a key safety finding.
Without multiple trials, you'd never know which version your users are actually going to see on any given day. It's like evaluating a manufacturing process based on a single batch — you'd never do that, and you shouldn't do it here either.
Step 3: Record everything — not just the final output
Evaluation systems capture a detailed transcript of what the AI did while completing the task: the original prompt, documents retrieved, intermediate reasoning steps, tool calls, and the final output.
This transcript may include:
The original prompt or instruction
Which documents or data sources the system retrieved
Intermediate reasoning steps and decisions
The final output
In pharma, this isn't just good engineering practice. It's the kind of traceability that quality and regulatory teams will eventually require — and it's significantly easier to build in from the start than to retrofit after someone asks for it during an audit.
Anthropic makes a point worth underscoring: reading transcripts regularly is one of the most valuable things a team can do. Not occasionally, not when something breaks — regularly. It builds intuition for how the system actually behaves, which is often quite different from how you assume it behaves. You wouldn't skip reviewing your clinical data because the summary statistics look fine. Don't skip reviewing your AI transcripts because the final output looks right.
Step 4: Grade the results with layered methods
After the system completes a task, you need to determine whether the result is acceptable. No single grading approach works on its own. Anthropic recommends combining three types — and in our experience, all three are necessary for pharma content.
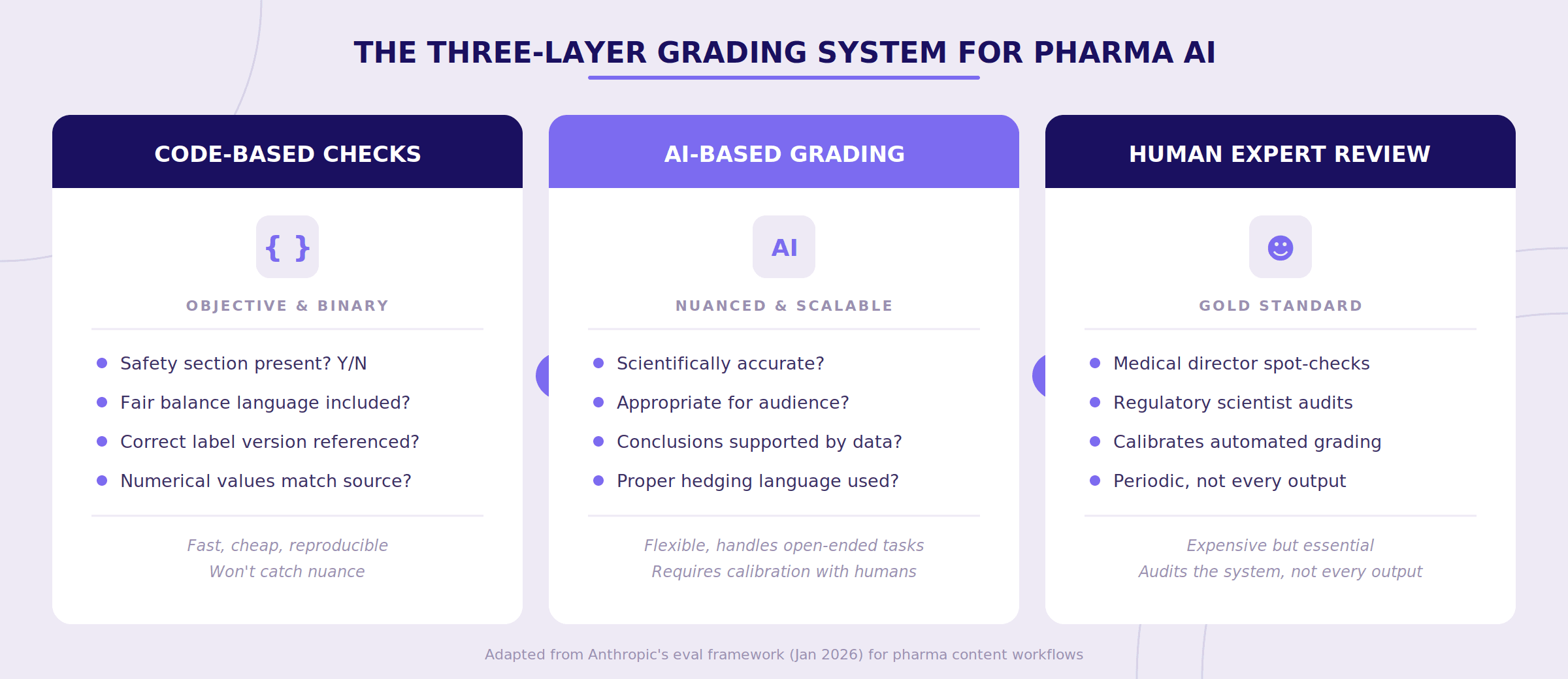
Code-based checks handle the objective, binary stuff. Did the summary include a safety section? Is the required fair balance language present? Did the system reference the correct version of the approved label? Are the numerical values (hazard ratios, p-values, confidence intervals) accurately reproduced from the source? These are fast, cheap, and reproducible. They won't catch everything, but they catch the things that should never be missed.
AI-based grading handles nuance. Is the clinical summary scientifically accurate? Is the language appropriate for the intended audience? Are conclusions supported by the cited data? Does the output maintain appropriate hedging ("suggested" vs. "demonstrated" for a secondary endpoint)? Here, a second AI model evaluates the first one's output — think of it as automated peer review. It's not perfect, but it scales in a way that human review alone cannot.
Human expert review keeps the entire system calibrated. A medical director or regulatory scientist periodically reviews a sample of outputs and the automated grades. This ensures that code-based and model-based grading haven't drifted from what actual scientific experts would consider acceptable. You don't need humans reviewing every output. You need humans auditing the system that reviews every output.
One important nuance from Anthropic: they specifically warn against designing graders that are too rigid about the steps an AI takes, versus the outcomes it produces. Agents frequently find valid approaches that designers didn't anticipate, and penalizing creativity defeats the purpose. This is good general advice — but in pharma it requires calibration. Some workflows are outcome-only (did the summary capture the right data?), while others are process-sensitive (did the system check the claim against the approved label, not against a random web search result?). Your eval framework needs to be thoughtful about which is which.
The Metric That Matters Most in Regulated Workflows
Here's where Anthropic's guide introduces a distinction that should genuinely change how pharma teams think about AI reliability.
They describe two metrics: pass@k and pass^k.
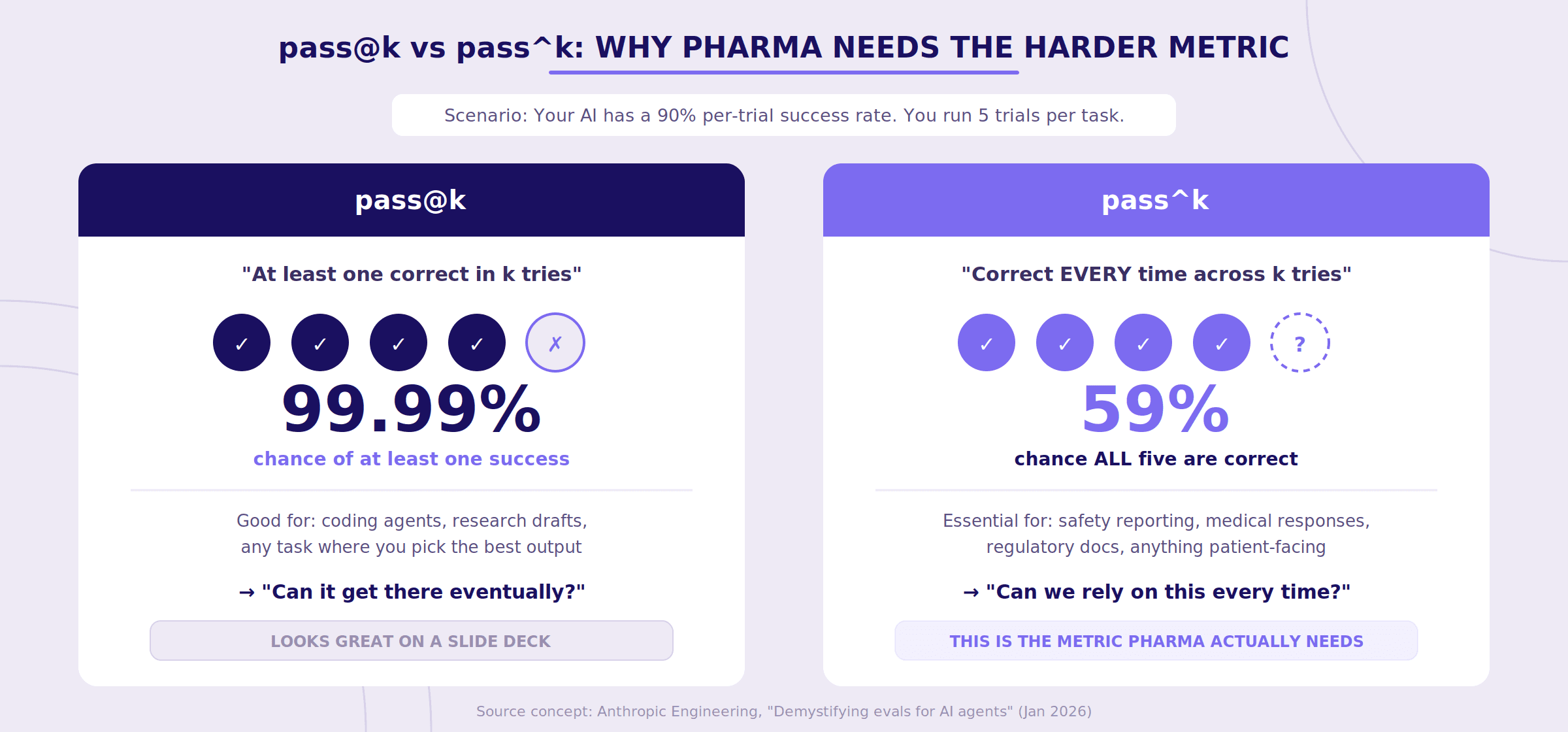
pass@k measures whether the system produces at least one correct result within k attempts. It's the "eventually gets it right" metric. For a software developer using a coding assistant, this is often perfectly fine — you generate a few solutions, pick the best one, move on.
pass^k measures whether the system produces the correct result every time across k attempts. It's the consistency metric.
In pharma, pass^k is almost always the metric that matters.
You don't want a medical information AI that usually includes the boxed warning. You want one that always includes it. You don't want a PV tool that correctly identifies serious adverse events on four out of five runs. You want five out of five.
To make this concrete: if your system has a 90% per-trial success rate and you run 5 trials, your pass@5 looks spectacular — roughly a 99.99% chance of at least one correct answer. But your pass^5 tells a very different story: about a 59% chance that all five are correct. That gap between "can do it" and "does it reliably" is precisely where regulatory risk lives.
An AI assistant that occasionally omits safety information — even if it eventually produces a correct answer on a subsequent run — can still cause real harm. The goal in regulated content workflows isn't occasional success. It's consistent reliability across every use.
Two Types of Evals You Need (And Why Most Teams Only Think About One)
Anthropic makes a distinction between capability evals and regression evals that maps directly to pharma's quality lifecycle — and it's a distinction most pharma AI teams are currently missing entirely.
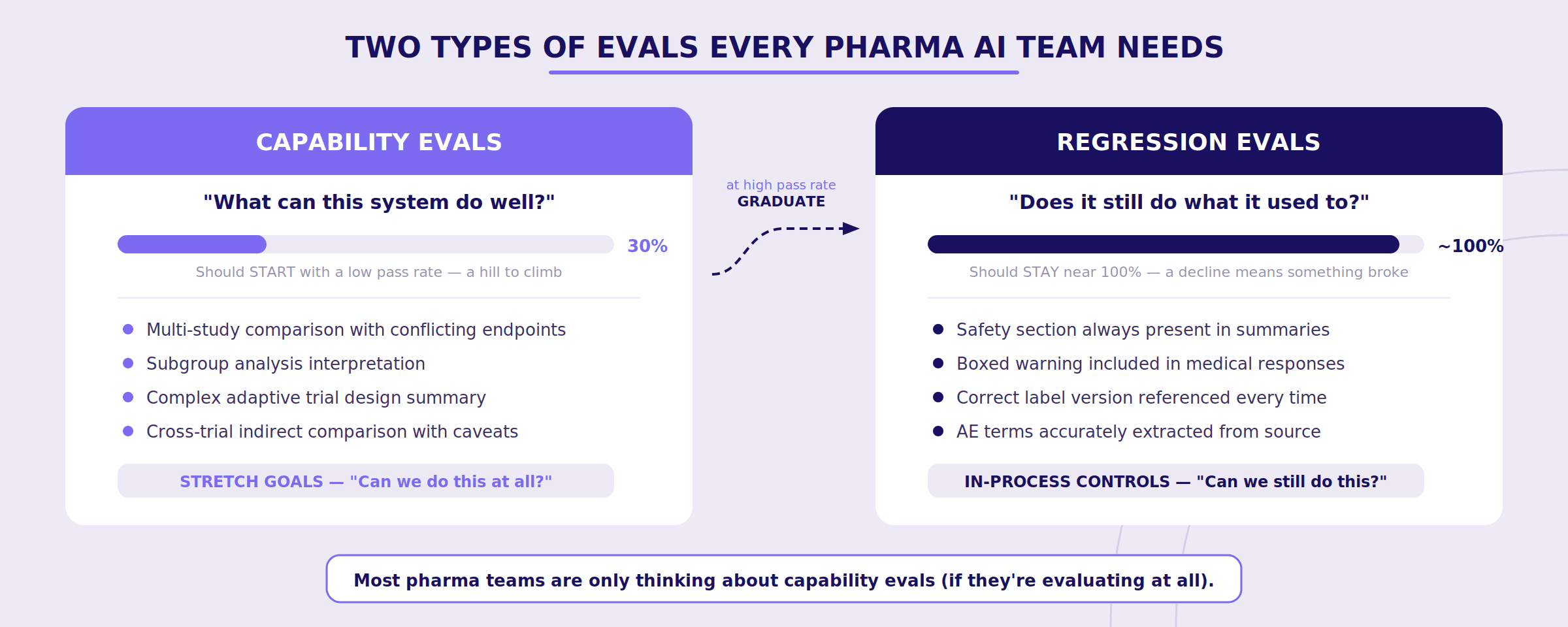
Capability evals ask: "What can this system do well?" These should start with a low pass rate — you're deliberately testing tasks the system struggles with, giving your team a hill to climb. Think of these as the stretch goals for your AI system:
Can it handle a multi-study comparison with conflicting endpoints?
Can it correctly interpret a subgroup analysis?
Can it summarize a study with a complex adaptive trial design?
Regression evals ask: "Does the system still do everything it used to?" These should have a nearly 100% pass rate. They're your in-process controls — a declining score means something broke and needs attention immediately.
Safety section still present in every summary?
Boxed warning still included in medical responses?
Correct label version still being referenced?
Here's the powerful part: as your team improves the system and capability evals start hitting high pass rates, those tasks graduate into your regression suite. What once measured "can we do this at all?" now measures "can we still do this reliably?" Your eval suite grows organically over time, and your quality bar only moves in one direction.
It's essentially the AI equivalent of how clinical development works: Phase I tasks (can we do this safely?) become Phase III tasks (can we do this reliably at scale?) and eventually become post-market surveillance (is it still working as expected?).
Anthropic also raises an important point about balanced problem sets that pharma teams should internalize. If you only test whether the system flags safety issues when it should, you might end up with a system that flags everything. They found this exact problem internally when building evals for web search: the challenge wasn't just getting the model to search when appropriate, but preventing it from searching when it shouldn't. For pharma, the equivalent might be an MLR review assistant that gets so aggressive about flagging potential issues that it becomes useless — crying wolf on every piece of content. You need eval tasks where the correct answer is "this is fine" just as much as tasks where the correct answer is "this needs attention."
The Honest Assessment: Where the Industry Is Getting This Wrong
In our experience working with pharma teams, we see two failure modes playing out with alarming regularity.
The first is over-engineering. Companies standing up elaborate AI governance committees, hiring consultants to build comprehensive frameworks, drafting policy documents — all before they've tested a single AI output in a structured way. They're building the org chart for a house that doesn't have a foundation. (Which is to say, they've purchased a governance platform — a spreadsheet with a logo and a $200K price tag — and called it progress.)
The second is under-engineering. Teams doing vibes-based quality assurance. A few people try the system, it seems good, someone says "LGTM" in a Slack thread, and that's the validation. This approach works until it doesn't. And in pharma, "until it doesn't" can mean a quality finding, a compliance event, or a very unpleasant conversation with your regulatory colleagues.
Both failure modes share the same root cause: teams haven't built the basic habit of structured, ongoing testing. They're either overthinking the governance or underthinking the testing, and in both cases, the AI system itself remains unexamined.
Why Layered Quality Matters: The Swiss Cheese Model
Anthropic borrows an analogy from safety engineering that pharma people should immediately recognize: the Swiss Cheese Model.
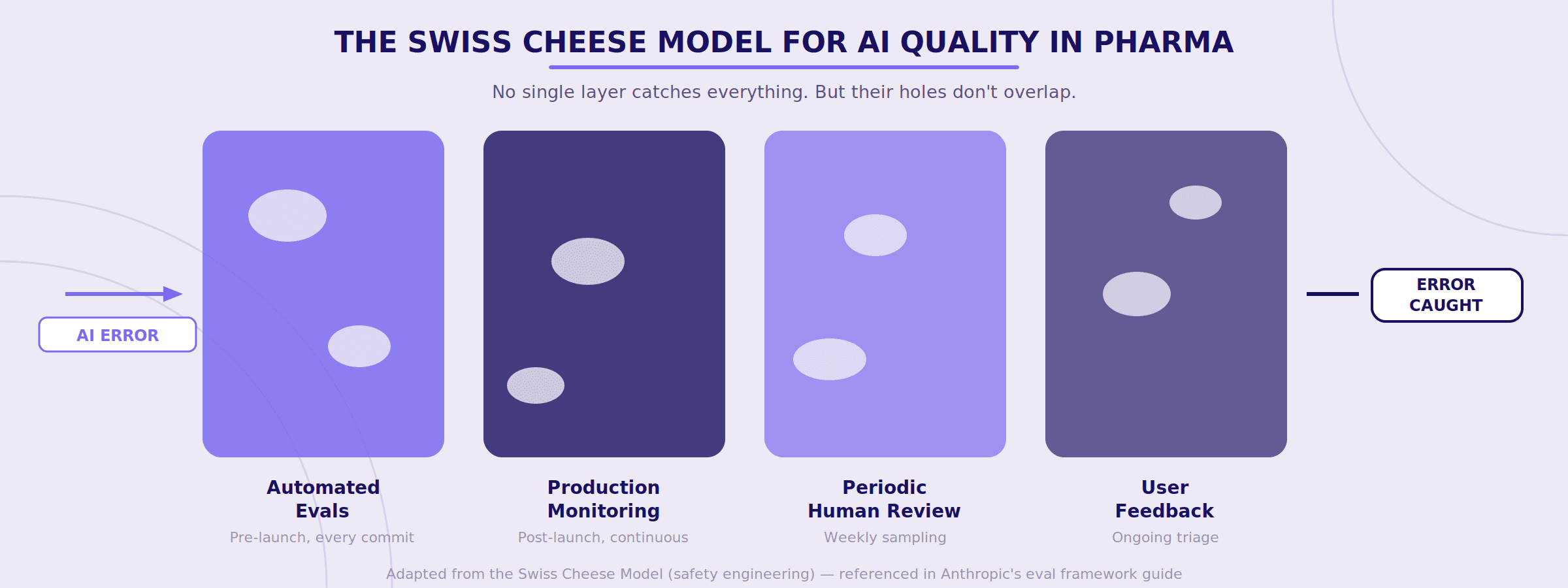
No single evaluation method catches everything. Automated evals miss things that production monitoring catches. Production monitoring misses things that periodic human review catches. Human review misses things that user feedback catches. But layered together, the holes in each layer don't align — and errors get caught before they reach patients.
For pharma organizations, this should feel familiar. It's essentially the same logic behind your existing quality systems — multiple checks, at different points, owned by different people, catching different types of failures. You already believe in this concept for your manufacturing processes. The question is whether you'll apply it to your AI systems.
Why This Matters for How We Build
Because we build for pharma teams and med comms agencies, the bar is inherently higher.
Pharmaceutical organizations operate in environments where scientific accuracy, traceability, and compliance aren't aspirational — they're mandatory. As AI systems become more embedded in content workflows, the need for consistent and measurable performance becomes critical.
Evaluation frameworks provide that structure. They allow teams to systematically test AI systems against real tasks, monitor performance over time, and catch regressions when models, prompts, or data sources change.
In practice, this shifts AI development from ad-hoc experimentation toward a more disciplined engineering process — the kind of process that regulated industries have always demanded but haven't yet applied to AI.
The pharma industry has spent decades building meticulous systems to ensure that when something changes in a manufacturing process, someone notices. Change control. Deviation management. CAPA. Entire quality organizations built on the premise that you cannot just assume things are working because they were working last quarter.
And yet many of the same companies with exquisitely detailed change control for their physical processes have no change control at all for AI systems that are starting to touch medical content, regulatory documents, and patient-facing information.
Evals are how you build that discipline for AI. Not as a one-time validation event that gets filed away and forgotten, but as an ongoing practice — the same way you'd never run a manufacturing line without in-process controls.
It's not the most exciting thing you can do with AI. But it might be the most important.
#AIinPharma #MedComms #LifeSciences
View All

Featured In
Why Life Sciences Needs Its Own Integrated Development Environment
Fragmented medical workflows limit AI. Vertical IDEs unify context, improve traceability, reduce risk, and enable reliable agent-driven content creation.

Arun Ramakrishnan
•
Featured In
Bridging The AI Divide: What It Really Takes To Get AI Agents Into Production
95% of AI pilots fail; success requires agents with context, tool integration, guardrails, usable interfaces, and focus beyond prototypes.
Udith Vaidyanathan
•
Featured In
When AI Meets Life Sciences: Separating Hype From Reality
AI turns chaotic data into insight at scale, but human judgment, integration challenges, and accuracy constraints define success.
Udith Viadyanathan
•






